
在 LLM 应用开发中,数据质量直接决定了 AI 的”智商”。无论是简历分析还是知识库向量化的前提,都是将其中的有效数据提取出来。
本文将以简历上传这一场景为例,详细讲解 Apache Tika 文档解析的优化实践,以及文件处理、异步分析等核心模块。
Apache Tika 简介
Apache Tika 是一个非常成熟的开源”内容分析工具箱”,它最大的特点是能从上千种不同格式的文件(如 PDF、Office 文档、音频、视频等)中,通过统一接口提取出文本和元数据(Metadata)。
技术选型对比
| 方案 | 格式支持 | 输出目标 | 核心优势 | 局限性/风险 | 结论 |
|---|---|---|---|---|---|
| 方案 | 格式支持 | 输出目标 | 核心优势 | 局限性/风险 | 结论 |
| Apache Tika | 极高 | 纯文本/XML | 统一 API;自动识别类型;可集成 OCR;社区生态极强 | 依赖包偏大;默认策略会带来噪音,需要定制 | 首选:全能型选手 |
| Apache POI | 中 (Office) | 结构化对象 | 对 Word/Excel 的结构控制细(段落、表格、样式) | 不支持 PDF;工程代码量大;多格式需拼装 | 适合仅处理 Excel/Word 报表 |
| PDFBox | 低 (PDF) | 文本/图片 | PDF 解析最稳定;支持坐标定位 | 只覆盖 PDF;扫描件需 OCR;多格式仍要拼装 | 适合作为 Tika 的底层组件 |
| Pandoc | 极高 | 跨格式转换 | 格式转换的”瑞士军刀”,排版还原度极高 | 需系统级安装(非纯 Java);并发性能较差 | 适合离线文档转换工具 |
| 在线解析 API | 高 | 结构化 JSON | 零维护;通常带 AI 增强识别 | 数据隐私风险;成本高;网络依赖 | 数据敏感场景不推荐 |
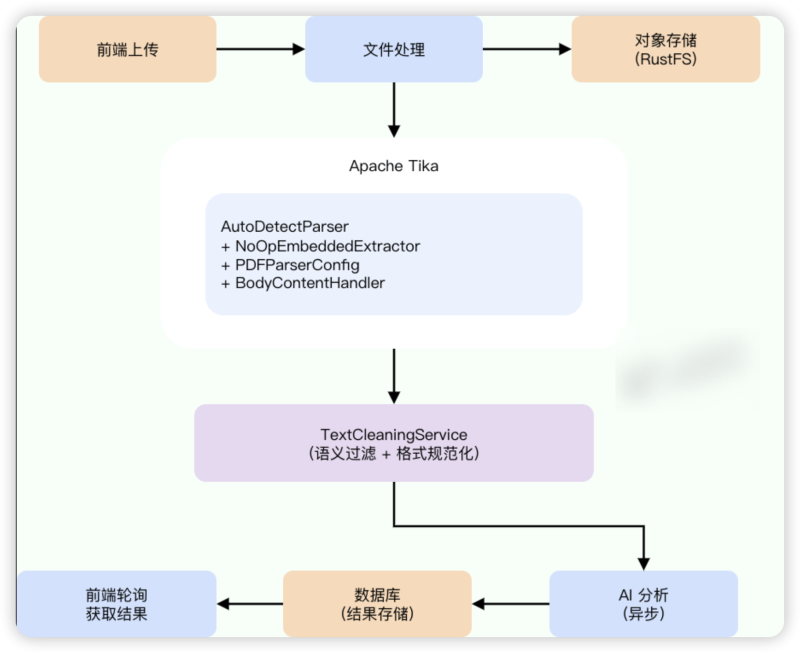
架构设计
整体架构
![图片[1]-基于 Tika 实现多格式内容提取与解析-MacFun is an interesting website.](https://www.macfun.org/wp-content/uploads/2026/04/image-11-1024x836.png)
双层清理策略
Tika 负责”解析”,TextCleaningService 负责”清洗”。两者分工明确,形成多层防御:
| 场景 | Tika 处理 | TextCleaningService 处理 |
|---|---|---|
| 场景 | Tika 处理 | TextCleaningService 处理 |
| Word 嵌入图片 | ✅ NoOp 跳过 | 兜底清理 |
| PDF 临时路径 | 部分场景仍会泄露 | ✅ 正则过滤 |
| 特殊符号分隔线 | ❌ 无法处理 | ✅ 正则过滤 |
| 连续空行 | ❌ 无法处理 | ✅ 格式压缩 |
| 未知噪音 | 可能遗漏 | ✅ 兜底保障 |
文件上传实现
Controller 入口
@RestController
@RequiredArgsConstructor
public class ResumeController {
private final ResumeUploadService uploadService;
@PostMapping(value = "/api/resumes/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public Result<Map<String, Object>> uploadAndAnalyze(
@RequestParam("file") MultipartFile file) {
Map<String, Object> result = uploadService.uploadAndAnalyze(file);
// 判断是否为重复简历
boolean isDuplicate = (Boolean) result.get("duplicate");
if (isDuplicate) {
return Result.success("检测到相同简历,已返回历史分析结果", result);
}
return Result.success(result);
}
}上传服务实现
ResumeUploadService 实现了完整的八步上传流程:
@Slf4j
@Service
@RequiredArgsConstructor
public class ResumeUploadService {
private final ResumeParseService parseService;
private final FileStorageService storageService;
private final ResumePersistenceService persistenceService;
private final FileValidationService fileValidationService;
private final AnalyzeStreamProducer analyzeStreamProducer;
private static final long MAX_FILE_SIZE = 10 * 1024 * 1024; // 10MB
/**
* 上传并分析简历(异步)
*/
public Map<String, Object> uploadAndAnalyze(MultipartFile file) {
// 1. 验证文件(非空、大小限制)
fileValidationService.validateFile(file, MAX_FILE_SIZE, "简历");
// 2. 检测并验证文件类型
String contentType = parseService.detectContentType(file);
validateContentType(contentType);
// 3. 检查简历是否已存在(基于 SHA-256 哈希去重)
Optional<ResumeEntity> existingResume = persistenceService.findExistingResume(file);
if (existingResume.isPresent()) {
return handleDuplicateResume(existingResume.get());
}
// 4. 解析简历文本(Tika + 文本清理)
String resumeText = parseService.parseResume(file);
if (resumeText == null || resumeText.trim().isEmpty()) {
throw new BusinessException(ErrorCode.RESUME_PARSE_FAILED,
"无法从文件中提取文本内容,请确保文件不是扫描版PDF");
}
// 5. 保存文件到对象存储(RustFS/S3)
String fileKey = storageService.uploadResume(file);
String fileUrl = storageService.getFileUrl(fileKey);
log.info("简历已存储到RustFS: {}", fileKey);
// 6. 保存简历记录到数据库(状态:PENDING)
ResumeEntity savedResume = persistenceService.saveResume(
file, resumeText, fileKey, fileUrl);
// 7. 发送分析任务到 Redis Stream(异步)
analyzeStreamProducer.sendAnalyzeTask(savedResume.getId(), resumeText);
// 8. 返回结果
return Map.of(
"resume", Map.of(
"id", savedResume.getId(),
"filename", savedResume.getOriginalFilename(),
"analyzeStatus", AsyncTaskStatus.PENDING.name()
),
"storage", Map.of(
"fileKey", fileKey,
"fileUrl", fileUrl,
"resumeId", savedResume.getId()
),
"duplicate", false
);
}
}上传流程图:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 文件验证 │────▶│ 类型识别 │────▶│ 去重检查 │
└─────────────┘ └─────────────┘ └─────────────┘
│
▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 返回结果 │◀────│ Redis Stream│◀────│ RustFS存储 │
└─────────────┘ └─────────────┘ └─────────────┘
▲ │
│ ▼
┌─────────────┐ ┌─────────────┐
│ 异步分析 │ │ 文本解析 │
└─────────────┘ └─────────────┘Tika 架构概览
Apache Tika 的设计理念是 “抽象与解耦” 。它本身并不直接处理每一种文件,而是充当一个”中间商”,封装了许多专业的底层库(如处理 PDF 的 PDFBox,处理 Office 的 POI)。
Tika 处理流程:
a、Detect(识别类型):输入 InputStream → 通过魔数/内容等判断 MIME 类型(不依赖后缀)
b、Parse(选择并解析):AutoDetectParser 检测到类型后,会把解析请求委派给对应的具体 Parser
c、Handle(输出内容):解析结果以事件流写入 ContentHandler,同时把元信息写入 Metadata 核心组件说明:
| 组件 | 作用 |
|---|---|
| 组件 | 作用 |
| AutoDetectParser | 结合 Detector 检测媒体类型(MIME),并委派给合适的具体 Parser 执行解析 |
| ContentHandler | 以 SAX 事件接收解析出的文档内容,并决定输出形式(纯文本/XHTML/限长等) |
| Metadata | 存放解析过程中提取的元信息(Content-Type、作者、标题、创建时间、页数等) |
| ParseContext | 向解析器传递上下文对象与配置(例如 PDF 解析策略、OCR 配置、EmbeddedDocumentExtractor 等) |
默认方式的问题
最简单的 Tika 使用方式:
// ❌ 不推荐:简单但有问题
Tika tika = new Tika();
String text = tika.parseToString(inputStream);问题一:嵌入资源污染 Word 文档中的图片会被提取为文件名引用:
姓名:张三
image1.jpeg ← 简历中的头像图片
image2.png ← 项目截图
工作经验:5年Java开发问题二:PDF 临时路径 PDF 中的内嵌资源会产生临时文件路径:
技术栈:Java, Spring Boot
file:///tmp/apache-tika-123456.html?query=0 ← 临时文件路径
熟悉微服务架构问题三:无长度限制 恶意文件可能产生超大文本,导致 OOM:
// 默认无限制,大文件可能撑爆内存
String text = tika.parseToString(hugeFile); // 💥 OOM优化方案:显式 Parser + Context
针对上述问题,我们采用显式配置的方式:
@Slf4j
@Service
public class DocumentParseService {
private static final int MAX_TEXT_LENGTH = 5 * 1024 * 1024; // 5MB
private final TextCleaningService textCleaningService;
/**
* 核心解析方法:使用显式 Parser + Context 方式解析文档
*
* 优化点:
* 1. 使用 BodyContentHandler 只提取正文内容
* 2. 禁用 EmbeddedDocumentExtractor,不解析嵌入资源(图片、附件)
* 3. 配置 PDFParserConfig,关闭图片和注释提取
* 4. 显式指定 Parser 到 Context,增强健壮性
*/
private String parseContent(InputStream inputStream)
throws IOException, TikaException, SAXException {
// ========== 1. 创建解析器 ==========
AutoDetectParser parser = new AutoDetectParser();
// ========== 2. 创建内容处理器 ==========
// BodyContentHandler:只提取正文,忽略元数据
// 参数 MAX_TEXT_LENGTH:限制最大文本长度,防止 OOM
BodyContentHandler handler = new BodyContentHandler(MAX_TEXT_LENGTH);
// ========== 3. 创建元数据容器 ==========
Metadata metadata = new Metadata();
// ========== 4. 创建解析上下文 ==========
ParseContext context = new ParseContext();
// 🔑 关键配置 1:将 Parser 注册到 Context
// 某些解析器需要递归调用自己处理嵌套文档
context.set(Parser.class, parser);
// 🔑 关键配置 2:禁用嵌入文档提取
// 这是解决"图片引用污染"的关键!
context.set(EmbeddedDocumentExtractor.class,
new NoOpEmbeddedDocumentExtractor());
// 🔑 关键配置 3:PDF 专用配置
PDFParserConfig pdfConfig = new PDFParserConfig();
pdfConfig.setExtractInlineImages(false); // 不提取内嵌图片
// 注意:Tika 2.9.2 中 setExtractAnnotations 方法可能不存在,关闭图片提取已足够
context.set(PDFParserConfig.class, pdfConfig);
// ========== 5. 执行解析 ==========
parser.parse(inputStream, handler, metadata, context);
// ========== 6. 文本清理 ==========
return textCleaningService.cleanText(handler.toString());
}
}NoOpEmbeddedDocumentExtractor 详解
这是解决嵌入资源污染的核心类:
/**
* 空操作的嵌入文档提取器
* 用于禁用 Tika 对嵌入资源(图片、附件等)的解析
*/
@Slf4j
public class NoOpEmbeddedDocumentExtractor implements EmbeddedDocumentExtractor {
/**
* 是否应该解析嵌入文档
*/
@Override
public boolean shouldParseEmbedded(Metadata metadata) {
// 记录跳过的嵌入文档(使用字符串常量,兼容不同 Tika 版本)
String resourceName = metadata.get("resourceName");
if (resourceName != null) {
log.debug("Skip embedded document: {}", resourceName);
}
return false;
}
/**
* 解析嵌入文档(空实现)
*/
@Override
public void parseEmbedded(InputStream stream, ContentHandler handler,
Metadata metadata, boolean outputHtml) {
// 空实现,不执行任何操作
// 由于 shouldParseEmbedded 返回 false,此方法不会被调用
}
}工作原理: Tika 在解析过程中会调用 EmbeddedDocumentExtractor 接口: 1shouldParseEmbedded() – 询问是否要处理嵌入资源(返回 false 直接跳过) 2parseEmbedded() – 实际处理嵌入资源(因上一步返回 false 不会被调用) 哪些资源会被跳过?
| 文档类型 | 嵌入资源示例 | 默认行为 | 使用 NoOp 后 |
|---|---|---|---|
| 文档类型 | 嵌入资源示例 | 默认行为 | 使用 NoOp 后 |
| Word (DOCX) | 图片、图表、OLE 对象 | 输出 image1.jpeg | 跳过 |
| 内嵌图片、附件 | 输出临时路径 | 跳过 | |
| Excel | 嵌入图表、图片 | 输出引用 | 跳过 |
| PPT | 幻灯片图片 | 输出文件名 | 跳过 |
ContentHandler 的选择
Tika 提供多种 ContentHandler,适用不同场景:
// 1. BodyContentHandler - 只提取正文(推荐用于简历)
BodyContentHandler bodyHandler = new BodyContentHandler(maxLength);
// 2. ToXMLContentHandler - 输出 XML 格式(保留结构)
ToXMLContentHandler xmlHandler = new ToXMLContentHandler();
// 3. WriteOutContentHandler - 直接写入 Writer
WriteOutContentHandler writerHandler = new WriteOutContentHandler(writer);
// 4. 默认 ContentHandler - 提取所有内容(包括元数据)
ContentHandler defaultHandler = new DefaultHandler();为什么选择 BodyContentHandler?
┌─────────────────────────────────────┐
│ Word 文档结构 │
├─────────────────────────────────────┤
│ [元数据] 作者: 张三, 创建时间: ... │ ← DefaultHandler 会提取
├─────────────────────────────────────┤
│ [正文] │
│ 姓名:张三 │ ← BodyContentHandler 只提取这部分
│ 工作经验:5年 │
│ 技能:Java, Spring Boot │
├─────────────────────────────────────┤
│ [页脚] 第1页 │ ← DefaultHandler 会提取
└─────────────────────────────────────┘解析效果对比
原始简历(Word 格式):
● 包含头像图片
● 包含项目截图
● 包含分隔线 默认解析结果:
image1.jpeg
张三
联系方式:138xxxx1234
image2.png
image3.jpeg
---
工作经验
XXX 公司 - 高级工程师
file:///tmp/tika-123.html?query=0
负责系统架构设计优化后解析结果:
张三
联系方式:138xxxx1234
工作经验
XXX 公司 - 高级工程师
负责系统架构设计文本清理服务
清理策略实现
@Service
public class TextCleaningService {
// ========== 预编译正则表达式(性能优化)==========
/**
* 图片文件名行:image123.png
* 整行匹配,防止误删正文中的文件名字符串
*/
private static final Pattern IMAGE_FILENAME_LINE =
Pattern.compile("(?m)^image\\d+\\.(png|jpe?g|gif|bmp|webp)\\s*$");
/**
* HTTP/HTTPS 图片链接
* 支持 URL 查询参数,大小写不敏感
*/
private static final Pattern IMAGE_URL =
Pattern.compile("https?://\\S+?\\.(png|jpe?g|gif|bmp|webp)(\\?\\S*)?",
Pattern.CASE_INSENSITIVE);
/**
* 文件协议 URL(Tika PDF 临时文件路径等)
*/
private static final Pattern FILE_URL =
Pattern.compile("file:(//)?\\S+", Pattern.CASE_INSENSITIVE);
/**
* 分隔线:---, ___, ***, ===
* 整行匹配,至少 3 个连续符号
*/
private static final Pattern SEPARATOR_LINE =
Pattern.compile("(?m)^\\s*[-_*=]{3,}\\s*$");
/**
* 控制字符(不可见字符)
* 保留换行符 \n (0x0A) 和制表符 \t (0x09)
*/
private static final Pattern CONTROL_CHARS =
Pattern.compile("[\\u0000-\\u0008\\u000B\\u000C\\u000E-\\u001F]");
/**
* HTML 标签
*/
private static final Pattern HTML_TAGS =
Pattern.compile("<[^>]+>");
/**
* 清理和规范化文本内容
*
* <p>语义级过滤(简历场景化):</p>
* <ul>
* <li>去除控制字符</li>
* <li>去除图片文件名(整行匹配)</li>
* <li>去除图片链接</li>
* <li>去除文件协议路径</li>
* <li>去除符号分隔线</li>
* </ul>
*
* <p>格式级清理:</p>
* <ul>
* <li>规范化换行符</li>
* <li>去除行尾空格,保留空行(保持段落结构)</li>
* <li>压缩连续空行(最多保留 2 个换行符)</li>
* </ul>
*
* <p>作为 RAG/AI 分析前的"保险层",确保文本质量</p>
*/
public String cleanText(String text) {
if (text == null || text.isBlank()) {
return "";
}
String t = text;
// ========== 第一层:语义去噪 ==========
t = CONTROL_CHARS.matcher(t).replaceAll("");
t = IMAGE_FILENAME_LINE.matcher(t).replaceAll("");
t = IMAGE_URL.matcher(t).replaceAll("");
t = FILE_URL.matcher(t).replaceAll("");
t = SEPARATOR_LINE.matcher(t).replaceAll("");
// ========== 第二层:格式规范化 ==========
// 统一换行符
t = t.replace("\r\n", "\n").replace("\r", "\n");
// 去掉行尾空格和制表符,保留空行(保持段落结构)
t = t.replaceAll("(?m)[ \t]+$", "");
// 压缩连续空行:最多保留 2 个换行符(即一个空行)
t = t.replaceAll("\\n{3,}", "\n\n");
return t.strip();
}
/**
* 清理文本并限制最大长度
*/
public String cleanTextWithLimit(String text, int maxLength) {
String cleaned = cleanText(text);
if (cleaned.length() > maxLength) {
return cleaned.substring(0, maxLength);
}
return cleaned;
}
/**
* 清理文本并移除所有换行符(转为空格)
* 适用于需要单行显示的场景
*/
public String cleanToSingleLine(String text) {
if (text == null || text.isBlank()) {
return "";
}
return text
.replaceAll("[\\r\\n]+", " ")
.replaceAll("\\s+", " ")
.strip();
}
/**
* 移除 HTML 标签和常见 HTML 实体
*/
public String stripHtml(String text) {
if (text == null || text.isBlank()) {
return "";
}
return HTML_TAGS.matcher(text).replaceAll(" ")
.replace(" ", " ")
.replace("&", "&")
.replace("<", "<")
.replace(">", ">")
.replace(""", "\"")
.replace("'", "'")
.replaceAll("\\s+", " ")
.strip();
}
}清理效果对照表
| 清理项 | 正则表达式 | 说明 |
|---|---|---|
| 清理项 | 正则表达式 | 说明 |
| 控制字符 | [\u0000-\u0008\u000B\u000C\u000E-\u001F] | 去除不可见字符 |
| 图片文件名 | (?m)^image\d+.(png | jpe?g |
| 图片链接 | https?://\S+?.(png | jpe?g |
| 文件路径 | file:(//)?\S+ | Tika 生成的临时引用 |
| 分隔线 | (?m)^[-_*=]{3,}$ | 纯符号行 |
| HTML 标签 | <>+> | 移除 HTML 标签 |
文件去重机制
关于文件去重机制,我在 Spring Boot + RustFS 构建高性能 S3 兼容的对象存储服务这篇文章中已经详细介绍,还不太了解的,推荐回过头看看这篇文章。
异步分析流程
AI 分析简历通常需要 5-30 秒,同步处理会导致: ●用户等待时间过长 ●HTTP 连接超时 ●服务器资源阻塞 采用 Redis Stream 实现异步处理:
关于 Redis Stream 异步任务队列在本项目中的使用非常重要,我单独写了一篇文章详细介绍:基于 Redis Stream 的异步任务处理实现。
最佳实践
Tika 文档解析
● 不要使用简单模式:避免 new Tika().parseToString(),使用显式 Parser + Context
● 禁用嵌入资源:实现 NoOpEmbeddedDocumentExtractor 跳过图片/附件
● 限制文本长度:BodyContentHandler(maxLength) 防止 OOM
● PDF 专用配置:关闭 setExtractInlineImages(false)
● 防御性清理:Tika 输出后仍需 TextCleaningService 二次清理
文件处理
● 基于内容去重:使用 SHA-256(不推荐 MD5,这也是一个面试考点) Hash,而非文件名
● 流式处理:使用 InputStream,避免 getBytes()
● 文件名安全:清理特殊字符,防止路径注入
● 大小限制:业务层和配置层双重限制
异步处理
● 消费者组:使用消费者组支持多实例部署
● 重试机制:实现重试处理临时失败
● 消息确认:消息确认后再更新状态
● 队列限制:设置 MAXLEN 防止消息堆积
常见问题解决
● 中文乱码:设置 Metadata.CONTENT_ENCODING 为 UTF-8
● 解析超时:使用 ExecutorService 包装解析调用
● 内存溢出:限制 ContentHandler 最大长度 + 流式处理
● 特殊字符:使用正则过滤控制字符
● 扫描版 PDF:提示用户”请确保文件不是扫描版PDF”
总结
简历上传与解析是 AI 应用的第一道关口,数据质量直接影响后续分析效果。
核心要点:
● Apache Tika:使用显式 Parser + Context,禁用嵌入资源提取
● BodyContentHandler:只提取正文,限制最大长度防止 OOM
● NoOpEmbeddedDocumentExtractor:跳过图片/附件,避免噪音污染
● TextCleaningService:双层清理策略,语义去噪 + 格式规范化
● 文件去重:基于 SHA-256 Hash,避免重复分析
● RustFS 存储:使用 S3 兼容存储,支持文件管理
● 异步分析:Redis Stream 实现 AI 分析异步化
● 错误处理:针对不同异常类型进行差异化处理 通过本文的实践,你可以快速在 Spring Boot 项目中实现简历上传、解析和存储功能。
完整代码可参考项目源码中的以下文件:
● modules/resume/service/ResumeUploadService.java – 简历上传服务
● modules/resume/service/ResumeParseService.java – 简历解析服务
● infrastructure/file/DocumentParseService.java – 通用文档解析服务
● infrastructure/file/TextCleaningService.java – 文本清理服务
● infrastructure/file/NoOpEmbeddedDocumentExtractor.java – 嵌入资源提取器
● infrastructure/file/FileHashService.java – 文件哈希服务




暂无评论内容